I took some time today to configure my R experience. I’m mostly using R from Emacs using ESS (Emacs Speaks Statistics), which means I had to configure some settings there as well.
Previously, my settings only consisted of setting a customised directory in which to install my packages and an alias to start R without asking for saving the histroy when quitting. This I did by setting the following environment variable in my .bashrc and/or .zshrc, as well as an alias:
# Set the library path for R export R_LIBS_USER=${R_LIBS_USER}:~/Programmeren/R/lib if [ -n "$(/usr/bin/which R 2>/dev/null)" ]; then alias R="$(/usr/bin/which R) --no-save" fi |
However, Emacs didn’t pick up either of these variables, so high time to fix that. This meant creating two files with the following content:
~/.Rprofile:
# Set the default CRAN repository used by install.packages() options("repos" = c(CRAN = "http://cran-mirror.cs.uu.nl/")) |
~/.Renviron:
R_LIBS="~/Programmeren/R/lib" |
I added the following to my .emacs file to start R with the --no-save option:
(setq inferior-R-args "--no-save ") |
Additionally I have the following in there to turn on a spelling checker and have line-wraps enabled:
(add-hook 'ess-mode-hook (lambda () ;; Set pdflatex as the default command for Sweave (default: texi2pdf) (setq ess-swv-pdflatex-commands (quote ("pdflatex" "texi2pdf" "make"))) (auto-fill-mode t) (flyspell-prog-mode) )) |
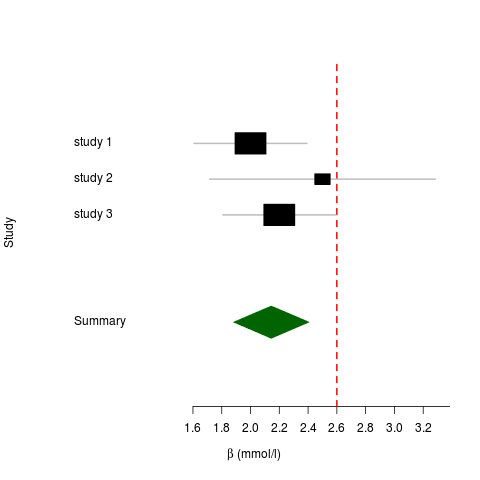
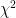 values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the
values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the