Yesterday I was working on ProbABEL, an open source package for running GWAS (genome-wide association studies). We use R-Forge and they provide us with a Subversion (SVN) server for revision control.
Some time ago we created a branch in which one of the co-developers is doing some major refactoring of the code. In the mean time I have been fixing bugs and adding new features to trunk. Now that the work in the refactoring branch comes to an end I thought it was high time to integrate the changes in trunk with the changes in the branch so that we can later promote the branch to trunk.
Since I had never done this before I decided to try the merge in the doc directory first, because I knew that in that directory nothing had changes since the branch was created, so all changes from trunk should be imported. At first I followed the SVN book instructions so I went into the doc dir in the branch and ran
$ svn merge ^/pkg/ProbABEL/doc
Unfortunately that didn’t work out. For some reasons conflicts appeared as wel as files that weren’t supposed to be there at all.
Thanks to Google and this blog post I found a solution. It boils down to explicitly telling SVN which revisions to use for the merge.
First I used
$ svn log | grep -C3 branch
to find out at which revision I created the branch:
------------------------------------------------------------------------
r864 | lckarssen | 2012-03-27 17:38:05 +0200 (Tue, 27 Mar 2012) | 1 line
Creating ProbABEL branch for code refactoring
Next I went to trunk and ran
$ svn update
At revision 987.
to find out at which revision trunk currently was. Back in the doc directory in the brach I ran
svn merge -r 864:987 ^/pkg/ProbABEL/doc
to merge al the changes since the branch was split off and it worked like a charm! All changes in trunk applied cleanly.
I then id the same for the other directories which also had changes in the branch. It turns out that when SVN find a conflict it is easier to postpone resolving the conflict because Emacs has a great SVN merge minor mode called SMerge! It highlights your changes vs. the incoming ones and allows you to select a resolution and move to the next conflict with a few easy keystrokes. After all conflicts have been resolved Emacs automtically removes the intermediate files SVN created and you are ready to commit.
Related Images:
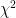 values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the
values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the