Back in January 2021 I ordered the reMarkable 2 e-paper note-taking “tablet”. I use it for two things: making notes and reading and annotating PDFs. Especially the note taking has changed significantly my working environment: no more stacks of paper notes lying all over my desk. No more trying to find a certain note in a notebook or on a piece of paper.
I do miss using my fountain pen, but the advantages, including having all your notes with you on your phone outweighs this. And, although the remarkable itself runs Linux, there is no Linux version of the desktop app. Unfortunately.
For some time I used community-developed tools, mainly to up- and download PDFs to and from the device. However, as the reMarkable software and file format evolved, more and more things stopped working, so I had to shift to another solution. I managed to install the Windows application in Wine. This works well and also allows me to e.g. share my reMarkable screen in video calls.
A few weeks ago, however, the app failed to start. I wasn’t sure if this was due to an update of the remarkable app itself or because the Wine version in Ubuntu 24.04 was upgraded from version 9.22 to 10.0rc2. It turned out to be the latter because my laptop definitely had an older (previously known good) version of the app that hadn’t been updated. Updating the Wine winehq-devel package, however, broke the app (a bug has been reported, see the list of links below).
Now, as you may have noted above, I was using the winehq-devel package, so I thought it was as simple as switching to the winehq-stable package. Unfortunately, that package is not available in Ubuntu 24.04. While looking for deb packages I found that the Wine HQ repo contained older package versions. So I decided to use the package pinning functionality of the Apt packaging system. I created the file /etc/apt/preferences.d/wine with the following contents:
Package: winehq-devel Pin: version 9.* Pin-Priority: 1000 Package: wine-devel Pin: version 9.* Pin-Priority: 1000 Package: wine-devel-amd64 Pin: version 9.* Pin-Priority: 1000 Package: wine-devel-i386:i386 Pin: version 9.* Pin-Priority: 1000
I determined the required package names by starting with the first one and then kept trying to install the winehq-devel package until it actually finished successfully. I set the pin priority to 1000, which means “causes a version to be installed even if this constitutes a downgrade of the package”, according to the apt_preferences man page. And, indeed, that is what Apt proposes:
The following additional packages will be installed: wine-devel wine-devel-amd64 wine-devel-i386:i386 The following NEW packages will be installed: winehq-devel The following packages will be DOWNGRADED: wine-devel wine-devel-amd64 wine-devel-i386:i386 0 upgraded, 1 newly installed, 3 downgraded, 0 to remove and 15 not upgraded. Need to get 229 MB of archives. After this operation, 8.414 kB disk space will be freed. Do you want to continue? [Y/n]
For completeness, these are the Wine packages that are currently installed on my system:
ii wine-devel 9.22~noble-1 amd64 WINE Is Not An Emulator - runs MS Windows programs ii wine-devel-amd64 9.22~noble-1 amd64 WINE Is Not An Emulator - runs MS Windows programs ii wine-devel-i386:i386 9.22~noble-1 i386 WINE Is Not An Emulator - runs MS Windows programs ii winehq-devel 9.22~noble-1 amd64 WINE Is Not An Emulator - runs MS Windows programs
As a side note, in order to make sure no other Wine settings were influencing my tests, I installed the reMarkable application in a fresh, dedicated WINEPREFIX:
WINEPREFIX=~/reMarkable/ wine ~/tmp/Downloads/reMarkable-3.16.1.901-win64.exe
After which I could start the application like this:
WINEPREFIX=~/reMarkable/ wine ~/reMarkable/drive_c/Program\ Files\ \(x86\)/reMarkable/reMarkable.exe
After this fresh install, the Gnome shell menu entry for the app didn’t work any more, so I had a look at the corresponding .desktop file in ~/.local/share/applications/wine/Programs/reMarkable/reMarkable.desktop. After some playing around I guess the problem was in missing double quotes around the path to the .exe file. The following works:
[Desktop Entry] Name=reMarkable Exec=env WINEPREFIX="/home/lennart/reMarkable" wine "/home/lennart/reMarkable/drive_c/Program Files (x86)/reMarkable/reMarkable.exe" Type=Application StartupNotify=true Path=/home/lennart/reMarkable/dosdevices/c:/Program Files (x86)/reMarkable Icon=94BF_reMarkable.0 StartupWMClass=remarkable.exe
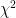 values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the
values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the