Today, as I browsed the entries for the reMarkable app in Wine’s AppDB, I noticed a “Gold” entry for Wine 10.0, which obviously sparked my attention. The important thing mentioned there is that the following workaround needs to be applied: WINEDLLOVERRIDES="qnetworklistmanager=b". In practice this means the following: if you want to start the reMarkable app from the commandline, you can do it like this:
However, I prefer to launch it from the regular Gnome menu, in which case I need to add this DLL override to the wine configuration. To do that, run
WINEPREFIX="/home/lennart/reMarkable"\
winecfg
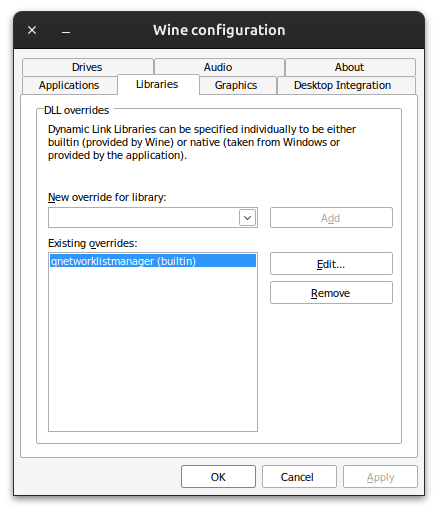
and select the Libraries tab. Add a new override for qnetworklistmanager and set it to builtin, as shown in the screenshot below. After that, launching the reMarkable app works as it always did.
Back in January 2021 I ordered the reMarkable 2 e-paper note-taking “tablet”. I use it for two things: making notes and reading and annotating PDFs. Especially the note taking has changed significantly my working environment: no more stacks of paper notes lying all over my desk. No more trying to find a certain note in a notebook or on a piece of paper.
I do miss using my fountain pen, but the advantages, including having all your notes with you on your phone outweighs this. And, although the remarkable itself runs Linux, there is no Linux version of the desktop app. Unfortunately.
For some time I used community-developed tools, mainly to up- and download PDFs to and from the device. However, as the reMarkable software and file format evolved, more and more things stopped working, so I had to shift to another solution. I managed to install the Windows application in Wine. This works well and also allows me to e.g. share my reMarkable screen in video calls.
A few weeks ago, however, the app failed to start. I wasn’t sure if this was due to an update of the remarkable app itself or because the Wine version in Ubuntu 24.04 was upgraded from version 9.22 to 10.0rc2. It turned out to be the latter because my laptop definitely had an older (previously known good) version of the app that hadn’t been updated. Updating the Wine winehq-devel package, however, broke the app (a bug has been reported, see the list of links below).
Now, as you may have noted above, I was using the winehq-devel package, so I thought it was as simple as switching to the winehq-stable package. Unfortunately, that package is not available in Ubuntu 24.04. While looking for deb packages I found that the Wine HQ repo contained older package versions. So I decided to use the package pinning functionality of the Apt packaging system. I created the file /etc/apt/preferences.d/wine with the following contents:
Package: winehq-devel
Pin: version 9.*
Pin-Priority: 1000
Package: wine-devel
Pin: version 9.*
Pin-Priority: 1000
Package: wine-devel-amd64
Pin: version 9.*
Pin-Priority: 1000
Package: wine-devel-i386:i386
Pin: version 9.*
Pin-Priority: 1000
I determined the required package names by starting with the first one and then kept trying to install the winehq-devel package until it actually finished successfully. I set the pin priority to 1000, which means “causes a version to be installed even if this constitutes a downgrade of the package”, according to the apt_preferences man page. And, indeed, that is what Apt proposes:
The following additional packages will be installed:
wine-devel wine-devel-amd64 wine-devel-i386:i386
The following NEW packages will be installed:
winehq-devel
The following packages will be DOWNGRADED:
wine-devel wine-devel-amd64 wine-devel-i386:i386
0 upgraded, 1 newly installed, 3 downgraded, 0 to remove and 15 not upgraded.
Need to get 229 MB of archives.
After this operation, 8.414 kB disk space will be freed.
Do you want to continue? [Y/n]
For completeness, these are the Wine packages that are currently installed on my system:
ii wine-devel 9.22~noble-1 amd64 WINE Is Not An Emulator - runs MS Windows programs
ii wine-devel-amd64 9.22~noble-1 amd64 WINE Is Not An Emulator - runs MS Windows programs
ii wine-devel-i386:i386 9.22~noble-1 i386 WINE Is Not An Emulator - runs MS Windows programs
ii winehq-devel 9.22~noble-1 amd64 WINE Is Not An Emulator - runs MS Windows programs
As a side note, in order to make sure no other Wine settings were influencing my tests, I installed the reMarkable application in a fresh, dedicated WINEPREFIX:
After this fresh install, the Gnome shell menu entry for the app didn’t work any more, so I had a look at the corresponding .desktop file in ~/.local/share/applications/wine/Programs/reMarkable/reMarkable.desktop. After some playing around I guess the problem was in missing double quotes around the path to the .exe file. The following works:
Ever since I had my new laptop (a Thinkpad T14s Gen4 AMD, bought in November 2023, currently running Ubuntu 24.04.1), I had tried to use it to play some movies with 5.1 surround sound via its HDMI port (connected to my 5.1 receiver), but I had never managed to make that work. Whereas on other systems the pavucontrol utility shows an HDMI 5.1 option (among others), no such thing was shown on this machine. It only showed “Play HiFi quality Music” and a “Pro Audio” option, neither of which mentioned anything about 5.1 surround sound. Moreover, the Ubuntu sound settings panel only showed the stereo option for speaker testing.
All those times before I had taken a quick look around the web to see if someone had written about a way to fix this. That didn’t seem to be the case and, given that my goal at those times was to watch a film, I usually switched to an alternative way to do that.
Until tonight. With some time to spare and no immediate intention to watch a film, I thought I’d try to see if I could dig a bit deeper. Surprisingly, this time it took me less than 10 minutes to find a forum post that helped me out.
In this topic on the Linux Mint forum user silmaril describes the same problem as I had, as well as the solution. Apparently, the ALSA Use Case Manager, or alsa-ucm tries to be smart and offer the right kind of configuration, but fails. In the solution they point to this page on the Arch wiki, which describes how to fix this. However, user silmaril took a more drastic route and simply used APT to remove the alsa-ucm-conf package. I did the same and after a
systemctl --user restart pipewire
The regular HDMI stereo and surround devices popped up in pavucontrol, and a test with a 5.1 film via VLC worked just fine.
No idea why I hadn’t found that topic on the Linux Mint forum before…
As I was running some manual package upgrades on my Ubuntu 24.04 server, I noticed that a kernel upgrade led to a long series of kernels being listed. This was strange, as there should have been only two or three. Closer inspection revealed that the update-grub command tries to find all kernels and also looks for kernels on ZFS datasets. Given that I extensively use ZFS, I was aware of that, and normally this is the behaviour I want.
However, in this case, my home server doesn’t have root on ZFS, but on a regular MD RAID mirror with LVM. Looking at the kernels listed during the upgrade, I noticed that update-grub was digging through all ZFS datasets and their snapshots on the server, including the backups sent to my home server from various other machines, some of which do have root on ZFS. All in all this led to a huge list of kernels and a kernel upgrade process that never seemed to end.
A quick web search pointed me to this AskUbuntu.com answer, which showed that the ZFS parsing code can be found in /etc/grub.d/10_linux_zfs. In there, I found the following code block (note, for improved readability I split the long command above the done over multiple lines and added corresponding \):
# List all the dataset with a root mountpointget_root_datasets(){localpools="$(zpool list | awk '{if (NR>1) print $1}')"for p in ${pools}; dolocalrel_pool_root=$(zpool get -H altroot ${p} | awk '{print $3}')if["${rel_pool_root}" = "-"]; thenrel_pool_root="/"fi
zfs list -H -o name,canmount,mountpoint -t filesystem | \
grep -E '^'"${p}"'(\s|/[[:print:]]*\s)(on|noauto)\s'"${rel_pool_root}"'$' | \
awk '{print $1}'done}
This function first lists all the ZFS pools on the system and then (with the last, long command above the done), for each of those, returns the filesystem datasets that can be mounted.
The solution was simple: because all backups from external systems end up as datasets below the remote_backups dataset on my storage pool, simply changed the last awk statement so that it only prints datasets that don’t match remote_backups by adding $1 !~ "remote_backups":
This way, the code would still work if I ever move this system to have root on ZFS, but now update-grub skips all backups and finds only the kernels relevant for my home server :-).
As an avid Emacs user, I love to have my Emacs key bindings available in as many places as possible. For example, even though I still regularly use the arrow keys to move the cursor around, I also use Emacs’ Alt-f and Alt-b to move one word forward or back, respectively. Similarly, Ctrl-a to me doesn’t mean “select all”, but rather “go to the beginning of line” (like the Home key). And especially this latter keybinding has a huge potential to mess things up, e.g. when you follow it by typing text, because that will then overwrite the selected text, i.e. all text. And the only thing I really intended to do was to go to the beginning of the line.
Another clash: in Emacs Ctrl-k means “kill to end of line”, i.e. “delete everything from the cursor position up to the end of the current line”, but in Firefox it sends your cursor to the Search box (for those of you who, like me, still use that for searching instead of just typing your query in the address bar). Similarly, Ctrl-n moves one character forward in Emacs, but in Firefox it opens a new window.
Luckily for me, I have managed to tailor the settings of various tools and the Gnome desktop environment to accommodate at least some of the more common Emacs key bindings. Unfortunately, applications built using other frameworks, like the Signal and Mattermost desktop apps, don’t follow these settings.
Below are the settings I’m currently using. Most of them have been with me for several years at this point and have been migrated various Ubuntu Linux upgrades, so I hope they are complete. For the record, I’m currently running the 24.04 Noble Numbat release.
Gnome
Let’s start with the Gnome desktop environment. My Linux desktop of choice for roughly the past twenty years has been Ubuntu, which uses Gnome. There is a gsettings entry that allows you to enable Emacs key bindings in most Gnome/Gtk applications, including Thunderbird. The entry can be set by setting the “Emacs input” toggle in the Keyboard section of the Gnome Tweak tool, or directly on the command line with
gsettings set org.gnome.desktop.interface gtk-key-theme "Emacs"
The current value can be checked like this:
$ gsettings get org.gnome.desktop.interface gtk-key-theme
'Emacs'
The Arch Linux wiki also lists options for GTK-2.0 and GTK-3.0, but I haven’t got those configured (any more).
Gnome terminal
By default, Gnome terminal steals the Alt key and uses e.g. Alt-f to open the file menu. This can be turned off by going to the hamburger menu in the top right corner and under “Global” — “General” uncheck the box for “Enable mnemonics (such as Alt-F to open the File menu)”.
Shells (Bash, Zsh)
As Emacs has been around for so many years, many shells (well, actually, the readline library if I’m not mistaken) support the basic Emacs key bindings for editing the commands you type on the command line. Both Bash and Zsh use the Emacs bindings by default (others might do too, but I don’t have any experience with other shells, except tcsh a long long time ago). In fact, you have to run set -o vi on order to be able to use Vim key bindings.
Byobu & Screen
I often use byobo as a terminal multiplexer. Like screen it likes to “steal” Ctrl-a as “attention” or “escape” key. Luckily, when the user presses Ctrl-a for the first time in Byobu, they are asked whether they’d like to use Emacs key bindings or not. My answer is obvious, and I generally give them Ctrl-o to use instead. This can be done via a menu by pressing F9 and selecting “Change escape sequence”.
Alternatively, this can be changed in the ~/.byoby/keybindings file by adding the following code:
# replace ctrl-A by ctrl-o
escape ^Oo
For screen the same line should be added to ~/.screenrc .
Firefox
My solution for Firefox is to replace the Ctrl key with the Alt key. This way, I can open new tabs with Alt-t, new windows with Alt-n, etc. Together with the Gnome settings for Emacs key bindings (see above), this means I can use Ctrl-a, Ctrl-f, Ctrl-b, etc. for moving the cursor in text fields, Ctrl-d for delete, etc. Interestingly enough, Alt-f and Alt-b — for “move one word forward” and “move one word backward”, respectively — keep working in text fields as well. Note that this also means that “Undo” is handled by Alt-z instead of Ctrl-z, which is fine with me because Ctrl-z is normally used to let applications run in the background (in the shell).
Unfortunately, some sites seem to define their own extra keybindings that interfere with my settings. For example, when creating or commenting on a Github issue, Ctrl-e inserts a backtick (`), instead of going to the end of line. I haven’t yet found out how to disable or overwrite that. I’m glad that I mainly use Gitlab, as it behaves properly.
To change the key, point to about:config in the address bar of the browser and find the entry ui.key.accelKey and change its value to 18. This is the code for the Alt key (see the documentation). You may want to set the entries ui.key.generalAccessKey and ui.key.menuAccessKey to 0 to disable e.g. using Alt for accessing the menus, but I haven’t done so myself.
There are, and have been, various Firefox extensions or other methods that allow(-ed) one to use Emacs for editing text in textfields like those used in forum posts, etc. However, the last one I used, “Emacs Everywhere” unfortunately doesn’t work yet with the Wayland window manager, although work seems to be on the way to fix that.
LibreOffice
Unfortunately I regularly have to edit MS Word documents (or their LibreOffice counterpart). Fortunately, Marcus Nitzschke created a customisation list for LibreOffice Writer that sets a series of basic Emacs movement key bindings! On his site he links to a Zip file that can be imported via Tools — Customize — Keyboard — Load. After that, the following keys should work in LibreOffice Writer (thanks to Marcus for this list):
The spinning disk pool on my home server uses a mirrored special device (for storing metadata and small blocks, see also this blog post at Klara Systems) based on two NVMe SSDs. Because my home server only has two M.2 slots and I wanted to have a pure SSD ZFS pool as well, I partitioned the SSDs. Each SSD has a partition for the SSD pool and one for the special device of the storage pool (which uses a mirror of spinning disks).
Note: This isn’t really a recommended production setup as you are basically hurting performance of both the special device and the SSD pool. But for my home server this works fine. For example, I use the special device’s small blocks functionality to store previews of the photo’s I store on my Nextcloud server. This makes scrolling through the Memories app’s timeline a breeze, even though the full-size photo’s are stored on the spinning disks.
Today, I noticed that the special device had filled up, and, given that there was still some unpartitioned space on the SSDs, I wondered if I could just expand the partition (using parted) used by the special device and then have the ZFS pool recognise the extra space. In the past I have expanded partition-based ZFS pools before, e.g. on after upgrading the SSD on my laptop, but I hadn’t tried this with a special device before.
After some experimentation, I can tell you: this works.
Here is how I tested this on a throw-away file-backed zpool. First create four test files: two for the actual mirror pool and two that I’ll add as a special device.
for i in{0..3} ; do truncate -s 1G file$i.raw ; done
ls -lh
total 4,0K
-rw-rw-r-- 1 lennart lennart 1,0G mrt 11 12:46 file0.raw
-rw-rw-r-- 1 lennart lennart 1,0G mrt 11 12:46 file1.raw
-rw-rw-r-- 1 lennart lennart 1,0G mrt 11 12:46 file2.raw
-rw-rw-r-- 1 lennart lennart 1,0G mrt 11 12:46 file3.raw
Create a regular mirror pool:
zpool create testpool mirror $(pwd)/file0.raw $(pwd)/file1.raw
zpool list -v testpool
I wasn’t sure whether I could just truncate the backing files for the special device to a larger size while they were part of the pool, so I detached them one by one and created new ones of 2GB, and then reattached them:
In my company, we have been using Expensify to manage small receipts, travel expenses, etc. Recently, however, I decided to switch to another platform that is part of the SAAS platform that our accountant uses. Even though it lacks some of the functionality provided by Expensify, having all receipts in a single location reduces the amount of time I have to spend on administrative tasks.
Every quarter Dutch companies have to file a VAT report, which meant I exported the Expensify reports to CSV files (to send to my accountant) and in PDF form, as a more “visual” backup, which lists the reported expenses, sorted in categories, and, importantly, also includes the scans on the various receipts.
As we changed accountants a couple of years ago, I wasn’t sure whether I had actually downloaded both the CSV and the PDF file for each Expensify report. Keeping records is required by Dutch law, so I decided to make sure and download all PDF files and back them up somewhere.
Unfortunately, the Expensify website doesn’t offer an option for bulk downloading of the PDF files. They do offer a kind of REST API (they call it the Integration Server), that I had played with years ago, so I decided to try that. Luckily, the credentials I had saved in my password manager still worked.
The process for downloading the PDFs consists of two steps:
Run a command to generate the reports, this returns the file names for the PDF files.
Use those names to download the PDFs
The first step took a couple of minutes to run and then listed the filenames for the PDF on stdout:
I’m not sure what the expensify_template.ftl file does in this command, but it was necessary to create that file locally, otherwise the curl call would return an error. I simply copied the example from the sample provided in the documentation for the Expensify Integration Server. I made a copy of the long list of PDF filenames output by the above command. A typical filename would look like this: exportc992bd79-aa4a-4b04-a76a-1149194bac94-34589514.pdf. Not very descriptive… As expected (confirmed in the web UI), there were 191 file names.
Next, step two: actually downloading the files. The basic call for that is:
Next, I used a loop to read each line from the pdflist file and fiddled a bit with the quotes so I could use the pdf variable in the Curl call and download each file:
cat pdflist | while read pdf; do
curl -X POST 'https://integrations.expensify.com/Integration-Server/ExpensifyIntegrations'\
-d "requestJobDescription={ 'type':'download', 'credentials':{ 'partnerUserID':'XXXXXXXXXX', 'partnerUserSecret':'YYYYYYYYYY' }, 'fileName':${pdf}, 'fileSystem':'integrationServer'} }"\
--data-urlencode 'template@expensify_template.ftl' --output ${pdf}done
This indeed gave me 191 Expensify report PDFs, with very uninformative names 😐 . To fix that I resorted to some more shell “scripting”. Every report has a title (usually something like “Small expenses 2020 Q4”) and by using the pdftotext utility, it looked like this was always on the third line of the pdftotext output. So I moved the original PDFs to a separate “archive” directory OriginalExports and ran the following to make a copy of each PDF to a new name that was equal to its title. My first attempt failed somewhat, because the number of renamed PDF files as smaller than the number of original PDFs. I guessed this would happen when two reports have the same name, and indeed, adding -i to the cp command to warn me of this showed I was right. As this was only happening for four files, I manually converted those.
for pdf in OriginalExports/export*.pdf; doecho ${pdf}title=$(pdftotext ${pdf} - | head -3 | tail -1 | tr "/""_")
cp -i ${pdf}"${title}.pdf"done
So there I had my backup of all receipts since we started using Expensify. And if the tax office or the accountant ever want to see those receipts, I am now sure I can provide them.
Recently, I noticed that changed files were not picked up by the Nextcloud client as fast as before. As a result I sometimes missed a file (or changes in a file) on my laptop that had been created on my desktop PC.
Today, I tried to run tail and got the following message:
tail: inotify resources exhausted
tail: inotify cannot be used, reverting to polling
This made me realise that the problem with the delayed client sync could be related to the inotify system for monitoring file changes.
It turns out there is a maximum to the number of inotify file watches:
Given that on my desktop the Nextcloud client syncs about 235 GB with my personal Nextcloud server and about 10 GB to two servers for work (including several Git repositories), I could imagine the 65536 watches is not enough. Indeed, manually increasing that number made file syncs more or less instantaneous again:
Today I returned to my desktop computer after having been away for a couple of days, during which I only used my laptop. Both machines run Ubuntu Linux, currently version 23.04.
The project I was going to work on required R, but for some reason R didn’t start. No error message, only an exit status of 1 and I was back at the shell prompt. Running R --version worked fine, but Rscript failed in the same way as regular R. I tried running R --vanilla, starting R as a different user, nothing helped.
Time to dig deeper. Make sure all Ubuntu packages are up to date. Reinstall the r-base and r-base-core packages, check whether those packages had been recently updated (no), check whether the package versions were identical to the ones on my laptop (where R worked fine). Nothing…
Maybe there is problem with a (missing) dynamic library? In the (distant) past I have had problems with that, so it is worth a shot:
That’s strange: I usually don’t have stuff installed in /usr/local. What is this AppProtection library doing there? And then it hit me: I recently (the last time I had used my desktop PC) had to install Citrix’s ICA client to do some remote desktop work for one of my clients. When I installed that package I was asked something about installing some sort of app protection. I had selected “yes”… With a feature named like that I should have known better…
Anyway, time to see if this shared library was indeed the problem. I moved the /usr/local/lib/AppProtection/ directory out of the way and tried to start R. All was fine and dandy again! Except that even an ls command now gave an error:
$ ls /usr/local/lib/AppProtection
ERROR: ld.so: object '/usr/local/lib/AppProtection/libAppProtection.so' from /etc/ld.so.preload cannot be preloaded (cannot open shared object file): ignored.
ls: cannot access '/usr/local/lib/AppProtection': No such file or directory
ERROR: ld.so: object '/usr/local/lib/AppProtection/libAppProtection.so' from /etc/ld.so.preload cannot be preloaded (cannot open shared object file): ignored.
Apparently (obviously?), something still tried to preload the library, even though it no longer existed. It turns out this was done in the file /etc/ld.so.preload:
/usr/local/lib/AppProtection/libAppProtection.so
Given that this was the only content of that file, I opted to just delete it. Finally, my system is back in a working state.
Conclusion: be more careful when installing stuff from external sources and definitely don’t install anything you don’t really need, like Citrix’s App Protection.
P.S. It turns out this was also the reason why the Mattermost app wasn’t running successfully any more.
For this blog, I use the Hemingway theme by Anders Norén. I really like it, but while writing a post with some long terminal outputs earlier today, I noticed that the <pre> blocks, in which code and terminal outputs are wrapped (by Org2Blog) get line-wrapped. This makes it difficult for the reader to interpret the blocks, especially when the block contents is e.g. an ASCII art-like table.
So I wanted to see if I could somehow fix this with some CSS. And it turns out you can! In the WordPress admin screen, go to “Appearance”, then “Additional CSS”. There I added the following and clicked on “Publish”:
.post-content pre {
word-wrap: normal;
overflow-x: auto;
white-space: pre;
}
This pice of code overwrites part of the theme’s CSS and makes sure the <pre> blocks get a horizontal scroll bar.