Introduction
The home directories of the servers I administer at work total about 6.5TB of data. The home directories are stored on a file server (using ext4 partitions) and served to the other server over NFSv3 with a bonded 1Gbps LAN link.
As you all know backups are a good idea but how to implement a backup strategy for this kind of data? We decided quite early that using tapes as backup medium was out of the question. We simply can’t afford them given the amount of disk space we need. Moreover, tapes usually require operator involvement and neither me nor my colleague feels like going to the data centre every week. Our idea was to back up to another server with enough disk space in a different part of the data centre. For off-site backups we can always make an annual (maybe monthly) backup either on tape at SurfSARA/BigGrid or on a remote server.
Before implementing a given strategy several things need to be known and tested. The major questions we wanted to have an answer to were:
- How often do we want to backup the data? Daily snapshots? Weekly? Monthly?
- How many of the backups mentioned above do we want to keep? And for how long?
- In order to answer these questions (given a roughly fixed amount of backup space) we need to know
- How much data changes per night/week/etc.
- How much duplication is there in the data? How many people store the same file (or blocks, if you go for block-level deduplication)?
- Is NFS/network speed a limiting factor when running the backups?
- Can the tool preserve additional file system attributes like POSIX ACLS?
Candidates
After looking around the web and looking back at my own experiences I came up with three possible candidates. Each of them allows for backup rotation and preserves Posix ACLs (so points 1 and 5 above have been taken care of).
- Bacula: enterprise-level backup application that I’ve used in combination with tapes in the past. Easily supports multiple clients, tape robots, etc. No deduplication. All metadata etc. are stored in a (MySQL) database, so restoring takes some effort (and don’t forget to make a backup of the database as well!).
- rsnapshot: based on rsync, makes snapshots using hard links. Easy to restore, because files are simply copied to the backup medium.
- rdiff-backup: similar to rsnapshot, but doesn’t allow for removal of intermediate backups after a given time interval. Consequently it was the first candidate to fall of my list.
- Obnam: a young tool that promises block level data deduplication. Stores backed up data in its own file format. Tools for browsing those archives are not really well developed yet.
Tests
Because I already had quite some experience with Bacula but none with the other two candidates (although I use rsync a lot) I decided to start a test run with Obnam, followed by a run with rsnapshot. These are the results:
Obnam
After backing up /home completely (which took several days!), a new run, several days later took (timing by the Linux time command):
Backed up 3443706 files, uploaded 94.0 GiB in 127h48m49s at 214.2 KiB/s average speed830 files; 1.24 GiB (0 B/s)
real 7668m56.628s
user 4767m16.132s
sys 162m48.739s
From the obname log file:
2012-11-17 12:41:34 INFO VFS: baseurl=/home read=0 written=0
2012-11-21 23:09:36 INFO VFS: baseurl=/backups/backup_home read=2727031576964 written=150015706142
2012-11-21 23:09:36 INFO Backup performance statistics:
2012-11-21 23:09:36 INFO * files found: 3443706
2012-11-21 23:09:36 INFO * uploaded data: 100915247663 bytes (93.9846482715 GiB)
2012-11-21 23:09:36 INFO * duration: 460128.627629 s
2012-11-21 23:09:36 INFO * average speed: 214.179341663 KiB/s
2012-11-21 23:09:36 INFO Backup finished.
2012-11-21 23:09:36 INFO Obnam ends
2012-11-21 23:09:36 INFO obnam version 1.2 ends normally
So: ~5 days for backing up ~100 GB of changed data… Load was not high on the machines, neither in terms of CPU, nor in terms of RAM. Disk usage in /backups/backup_home was 5.7T, disk usage of /home was 6.6T, so there is some dedup, it seems.
rsnapshot
A full backup of /home to (according to the log file):
[27/Nov/2012:12:55:31] /usr/bin/rsnapshot daily: started
[27/Nov/2012:12:55:31] echo 17632 > /var/run/rsnapshot.pid
[27/Nov/2012:12:55:31] mkdir -m 0700 -p /backups/backup_home_rsnapshot/
[27/Nov/2012:12:55:31] mkdir -m 0755 -p /backups/backup_home_rsnapshot/daily.0/
[27/Nov/2012:12:55:31] /usr/bin/rsync -a --delete --numeric-ids --relative --delete-excluded /home /backups/backup_home_rsnapshot/daily.0/localhost/
[28/Nov/2012:23:16:16] touch /backups/backup_home_rsnapshot/daily.0/
[28/Nov/2012:23:16:16] rm -f /var/run/rsnapshot.pid
[28/Nov/2012:23:16:16] /usr/bin/rsnapshot daily: completed successfully
So: ~1.5 days for a full backup of 6.3TB. An incremental backup a
day later took:
[29/Nov/2012:13:10:21] /usr/bin/rsnapshot daily: started
[29/Nov/2012:13:10:21] echo 20359 > /var/run/rsnapshot.pid
[29/Nov/2012:13:10:21] mv /backups/backup_home_rsnapshot/daily.0/ /backups/backup_home_rsnapshot/daily.1/
[29/Nov/2012:13:10:21] mkdir -m 0755 -p /backups/backup_home_rsnapshot/daily.0/
[29/Nov/2012:13:10:21] /usr/bin/rsync -a –delete –numeric-ids –relative –delete-excluded –link-dest=/backups/backup_home_rsnapshot/daily.1/localhost/ /home /backups/backup_home_rsnapshot/daily.0/localhost/
[29/Nov/2012:13:25:09] touch /backups/backup_home_rsnapshot/daily.0/
[29/Nov/2012:13:25:09] rm -f /var/run/rsnapshot.pid
[29/Nov/2012:13:25:09] /usr/bin/rsnapshot daily: completed successfully
So: 15 minutes… and the changed data amounted to 21GB.
This gave me a clear winner: rsnapshot! Not only is it very fast, but given its simple way of storing data restoring a backup of any file is quickly done.
We now also have answers to our questions: Our daily changing volume is of the order of ~ 100GB, there isn’t much data that can be deduplicated. We also monitored the network usage and, depending on the server load it can be limiting, but since a daily differential backup takes only 15-30 minutes that isn’t a problem.
For a remote backup sever that was connected with a 100Mbps line we did see that the initial backup took a very long time. We should try to get a faster connection to that machine.
The future
The next challenge we face is how to back up some of the large data sets we have/produce. These include aligned BAM files of next-generation sequencing data, VCF files of the same data, results from genomic imputations (both as gzip-ed text files and as binary files in DatABEL format). This also totals several TB. Luckily these files usually don’t change on a daily basis.
Related Images:
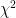 values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the
values in the output files. At the moment these are based on the LRT (likelihood ratio test), except where that doesn’t make sense (e.g. when using the